
TL;DR: 实测配备 48GB 内存的 M4 Pro 运行本地 Qwen 2.5 14B(4bit),通过 LM Studio 使用 Apple 原生的 MLX 框架相比常规的 GGUF 格式约有 15% 的性能提升。但对于参数量 32B 及以上的模型,单机推理速度仍稍显吃力。对于日常开发探索,48GB 大内存赋予了更高的天花板。
选购考量:为何升级至 48GB 内存的 M4 Pro
今年搭载 M4 Pro 芯片的 MacBook Pro 在众多视频评测中展现了许多亮点。相较于上一代的 M3 Pro 产品,这次升级更为显著。其中屏幕亮度提升到 SDR 1000 尼特,HDR 1600 尼特。接口全面升级为雷雳 5(Thunderbolt 5),当然,这也是个“战未来”的配置升级。
作为一名长期使用 M1 MacBook Pro 的用户,这台老设备的 CPU 性能对我来说其实绰绰有余,唯一的痛点是内存太小了。我经常在活动监视器中看到内存压力显示为黄色,这让我感到有些焦虑。设备使用起来其实没有明显的卡顿感,只是这次 M4 的性能提升同时碰到了国补,让我萌生了升级的念头。
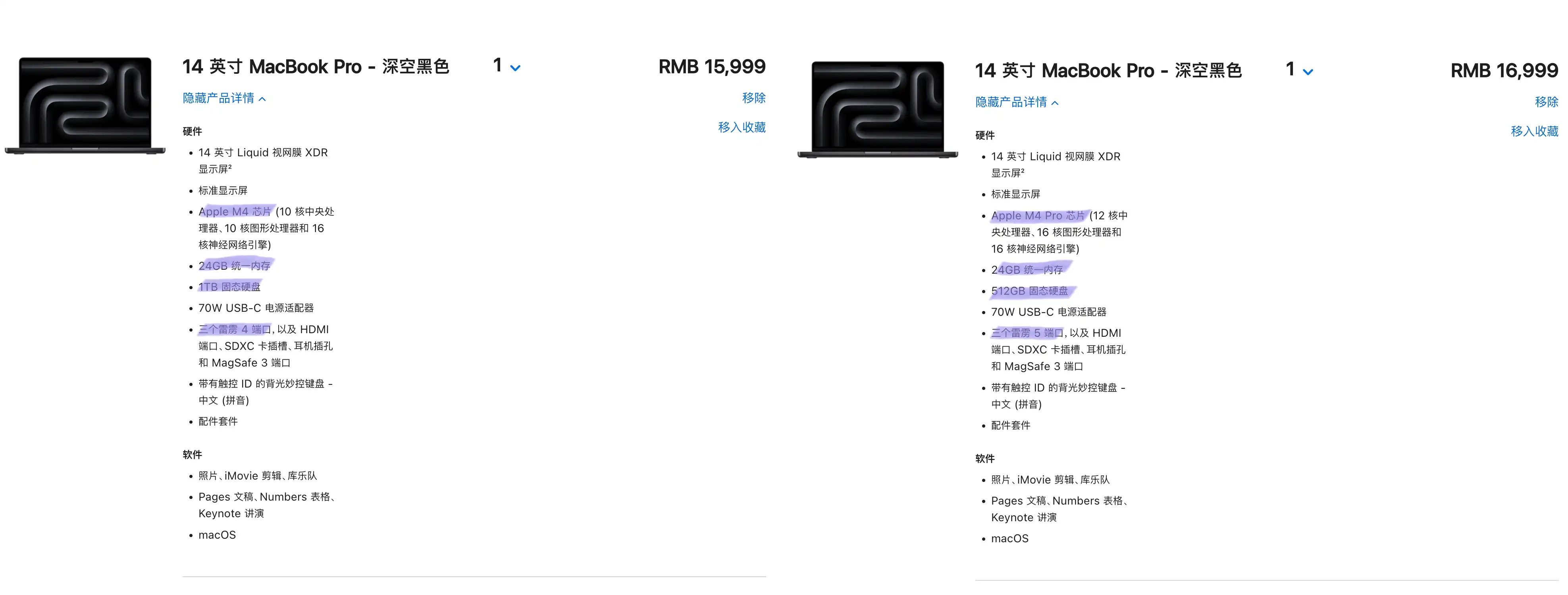
对比配置后发现,配备 24GB 内存的 M4 Pro MacBook Pro 售价为 16999 元,只比配备同等 24GB 内存的 M4 基础版贵 1000 元。在这微小的差价内,处理器、图形处理能力(GPU)和内存带宽等方面均有显著提升,这使得升级至 M4 Pro 版极具性价比。然而,我也发现国补的“M4 Pro 丐版”并不好抢。兜兜转转等了很久,我最终未能享受到国家补贴的优惠,而是直接在苹果的授权经销商处购买了一台内存定制升级至 48GB 的 M4 Pro 机器。
为何要选择 48G 内存呢?
- 浏览器重度使用习惯:我的 Chrome 标签页一般是等到实在放不下了才会去整理关闭。
- 探索本地大模型(LLM)部署:这是促使我加满内存的决定性因素。尽管当前环境下直接调用网络云端 API 可能更为高效,但 AI 模型的发展速度实在太快,我想亲自尝试在本地运行它们。例如,现在可以免费调用的开源模型 Qwen 2.5 7B,在能力上已经基本接近去年 OpenAI 的 GPT-3.5 Turbo。
只是没想到,这台笔记本电脑的内存配置突然成为了家中最高的计算节点。相比之下,我家里的 HomeLab 服务器(HP ProLiant MicroServer Gen10 Plus)也只有 32GB 的内存。
本地 LLM 实测:MLX vs GGUF 性能对比
为了测试这台 M4 Pro 在 AI 推理上的潜力,我选择了跨平台的本地大模型运行工具 LM Studio。
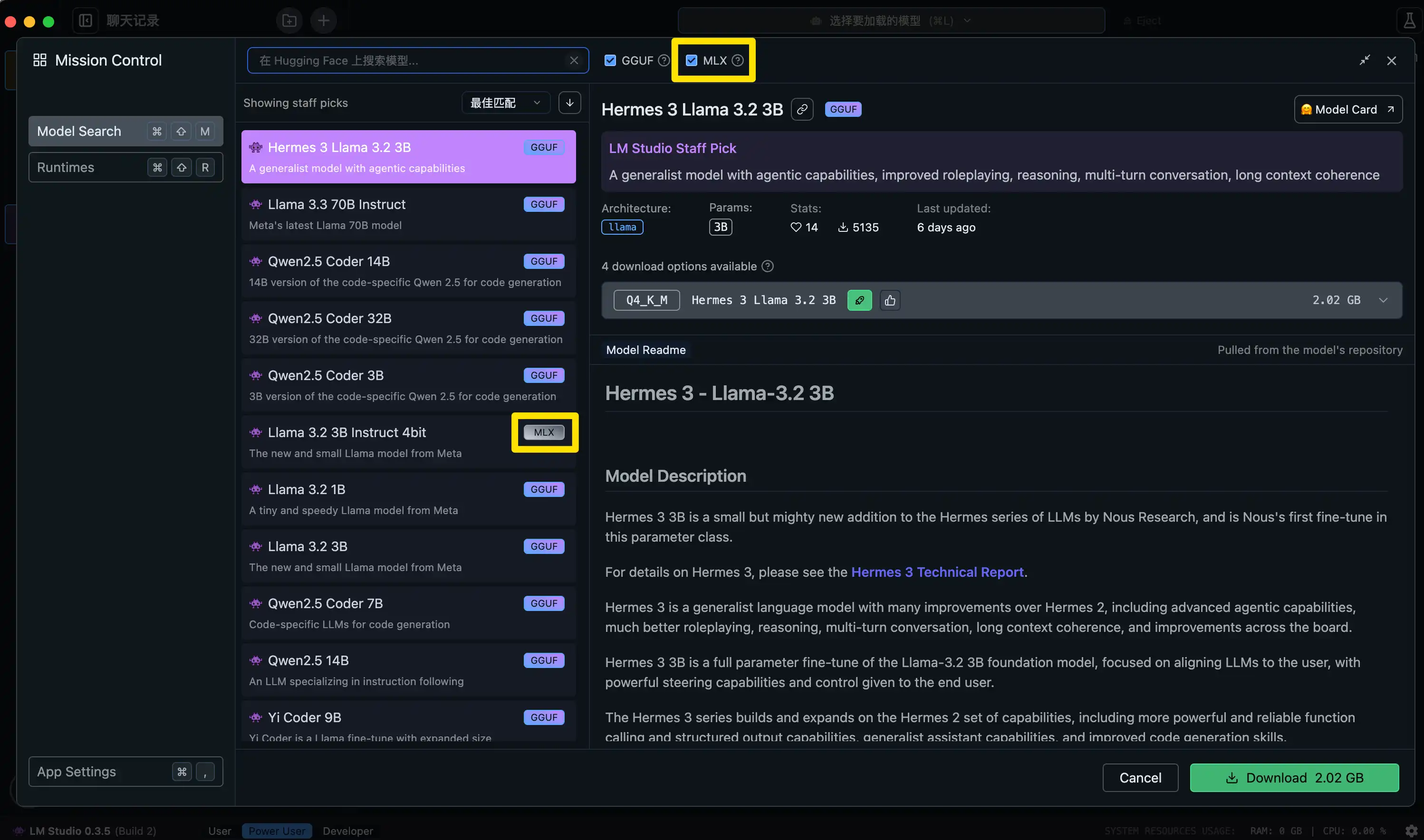
通过官方更新文档了解到,0.3.4 版本的 LM Studio 专门为 MLX 格式(Apple 专为自家芯片优化的开源机器学习框架)进行了标注和模型筛选。从理论设计上看,MLX 架构在苹果芯片设备上的底层调用效率应优于通用的 GGUF 格式。
为了验证这一点,我下载了 Qwen 2.5 14B(4bit 量化) 版本进行了推理对比。
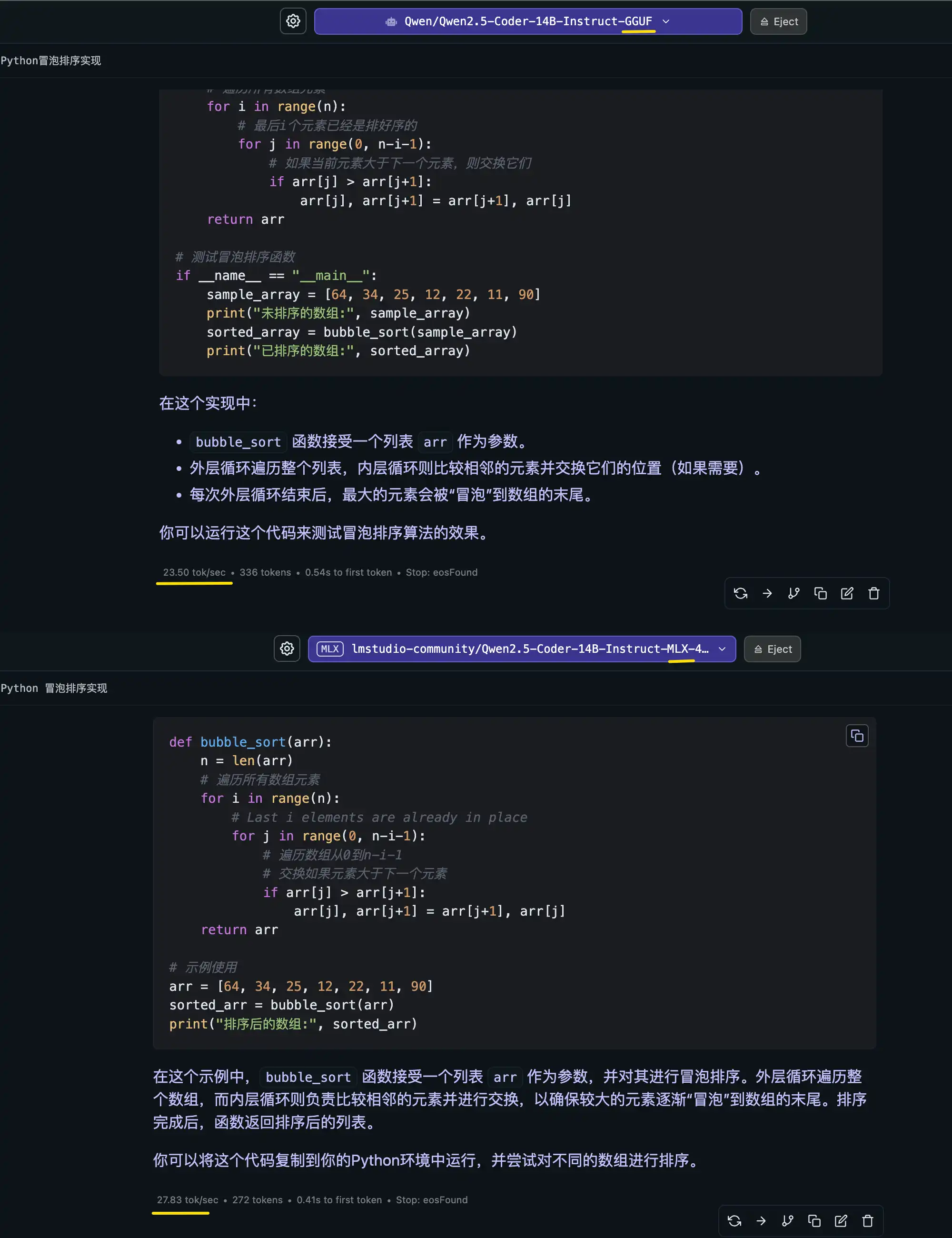
实测结果分析
- 生成速率提升有限:实测发现,加载使用 MLX 格式的模型,其 token 生成速度相比 GGUF 格式确实带来了 约 15% 左右的轻微性能提升。但在日常聊天的真实体感中,由于推理速度本身较快,这种 15% 的增幅感知并不十分显著。
- NPU 利用率疑问:此外,在整个推理过程中,即便使用了专门优化的 MLX 框架,我通过系统监控工具(如
asitop)也几乎未能观察到 M4 Pro 内置的 神经引擎(NPU)高度参与运算。依然主要依赖 GPU 和 CPU 矩阵。
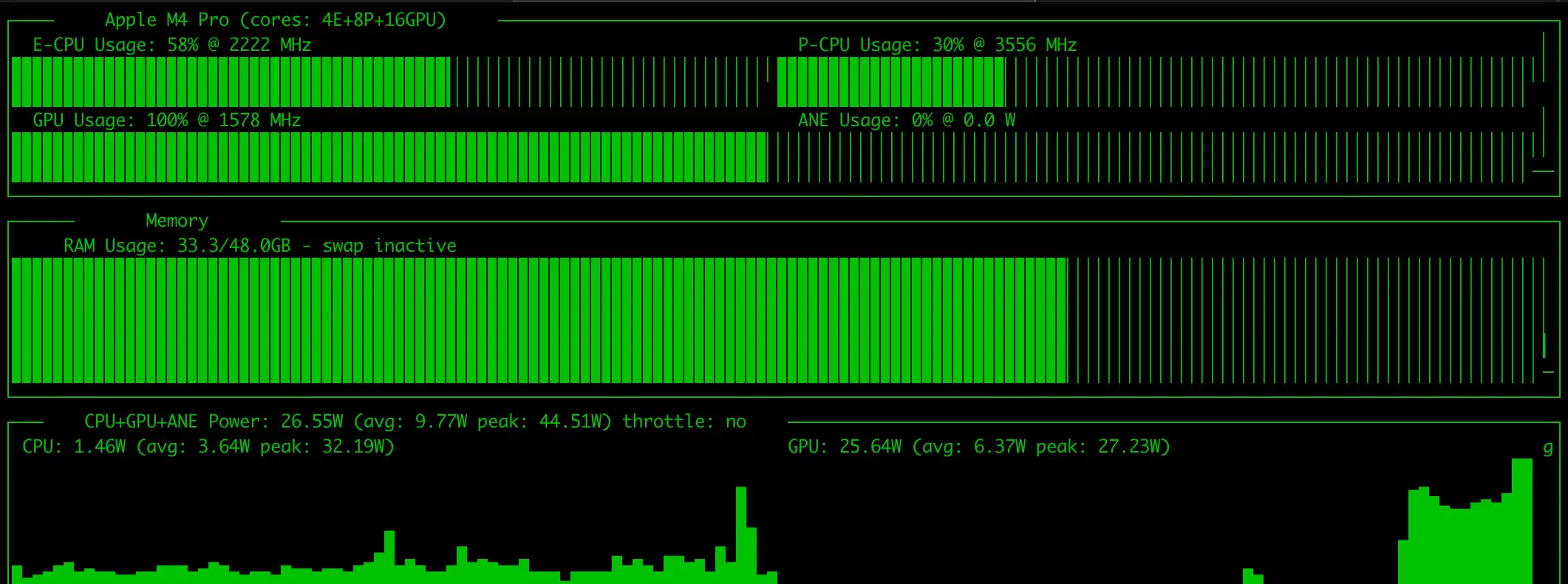
进一步针对更大规模的模型进行压力测试:对于参数量达到 32B 级别及以上的大模型,即便在拥有较高显存带宽的 M4 Pro 上运行,每秒生成的 token 数量也变得不太令人满意。这类超大参数模型在移动端芯片上的性能表现,距离丝滑的日常全天候辅助场景仍有距离。
结论与展望
总体而言,经过对本地大模型的初步体验,我发现 M4 Pro 相比之前的产品确实有显著提升,但并未给我带来如同当年初见 M1 MacBook Pro 时那种“跨时代”的突破性惊喜(特别是在 AI 本地推理的直观体感上)。
然而,不可否认的是,这高达 48GB 统一内存的超高配置,给了我一台随时随地部署各类开源模型测试的“移动机房”。未来随着 MLX 框架生态的进一步成熟,也许这些闲置算力能发挥出更大的探索价值,或许这才是此次升级最大的长远意义所在。