最近文生图和本地大语言模型工具的快速发展,为创作者和开发者提供了更多可能性。作为一名技术爱好者,我最近尝试了几款相关工具,包括文生图工具和本地LLM工具,以下是我的一些使用体验。
文生图工具体验
Mochi Diffusion
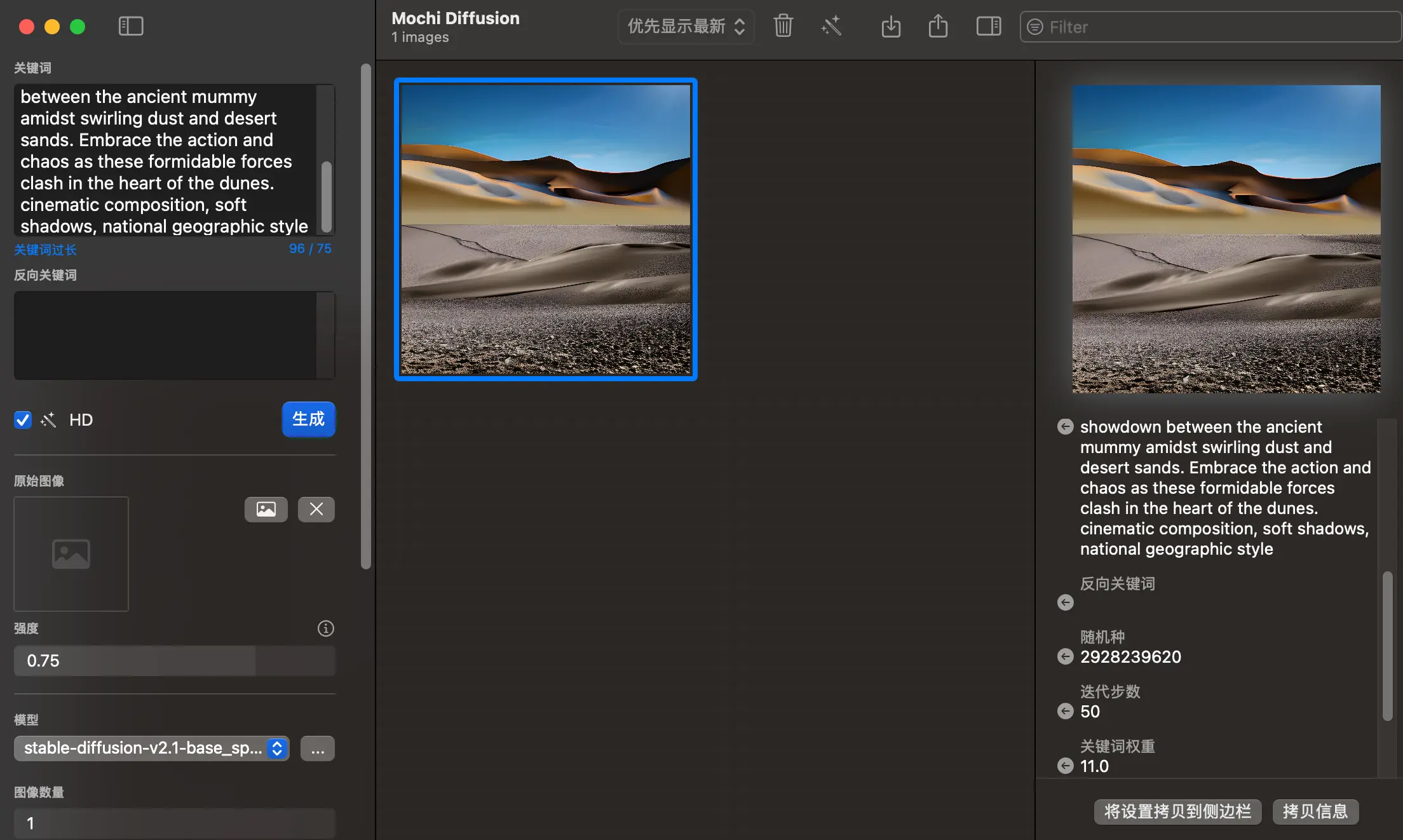
这是我第一次接触文生图工具,选择Mochi Diffusion的原因是它上手难度较低,适合新手。在Hugging Face上下载了两个模型后,生成的效果让我感稍稍有些抽象。整个生成过程没有使用GPU,完全依赖于CPU和NPU,这意味着即使没有高性能显卡,也能轻松运行。不过,生成速度相对较慢,也许是打开方式不对,主观不太推荐。
Draw Things
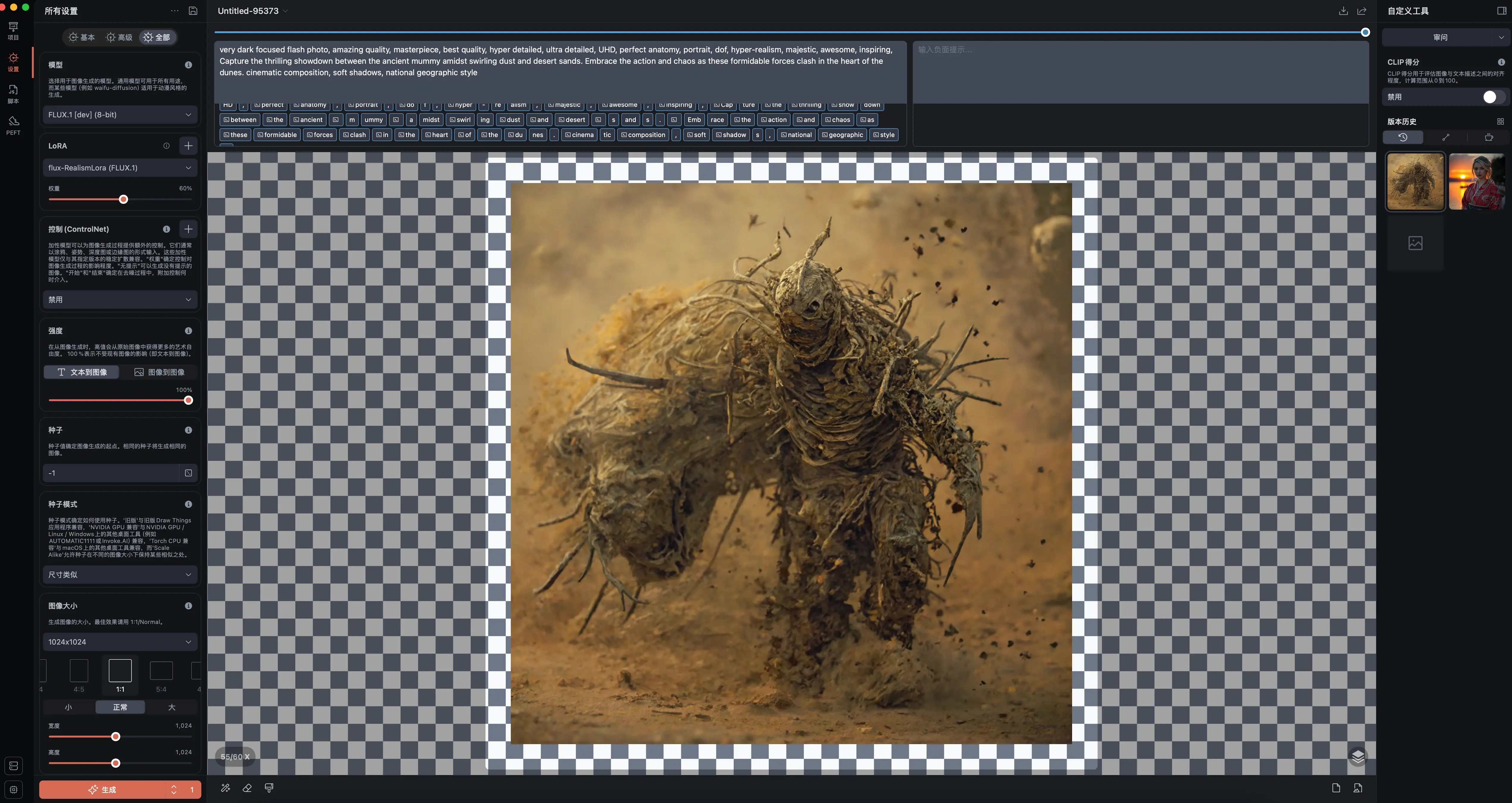
Draw Things是一个折中的解决方案,它提供了丰富的模型选择,并且支持用户自定义调整参数。此外,它还集成许多作者自己调整的模型,允许用户设置LoRA和ControlNet,功能非常完整。我个人认为,Draw Things是Mac用户的首选文生图工具,因为它在Mac系统上的表现非常稳定,且界面友好。
ComfyUI
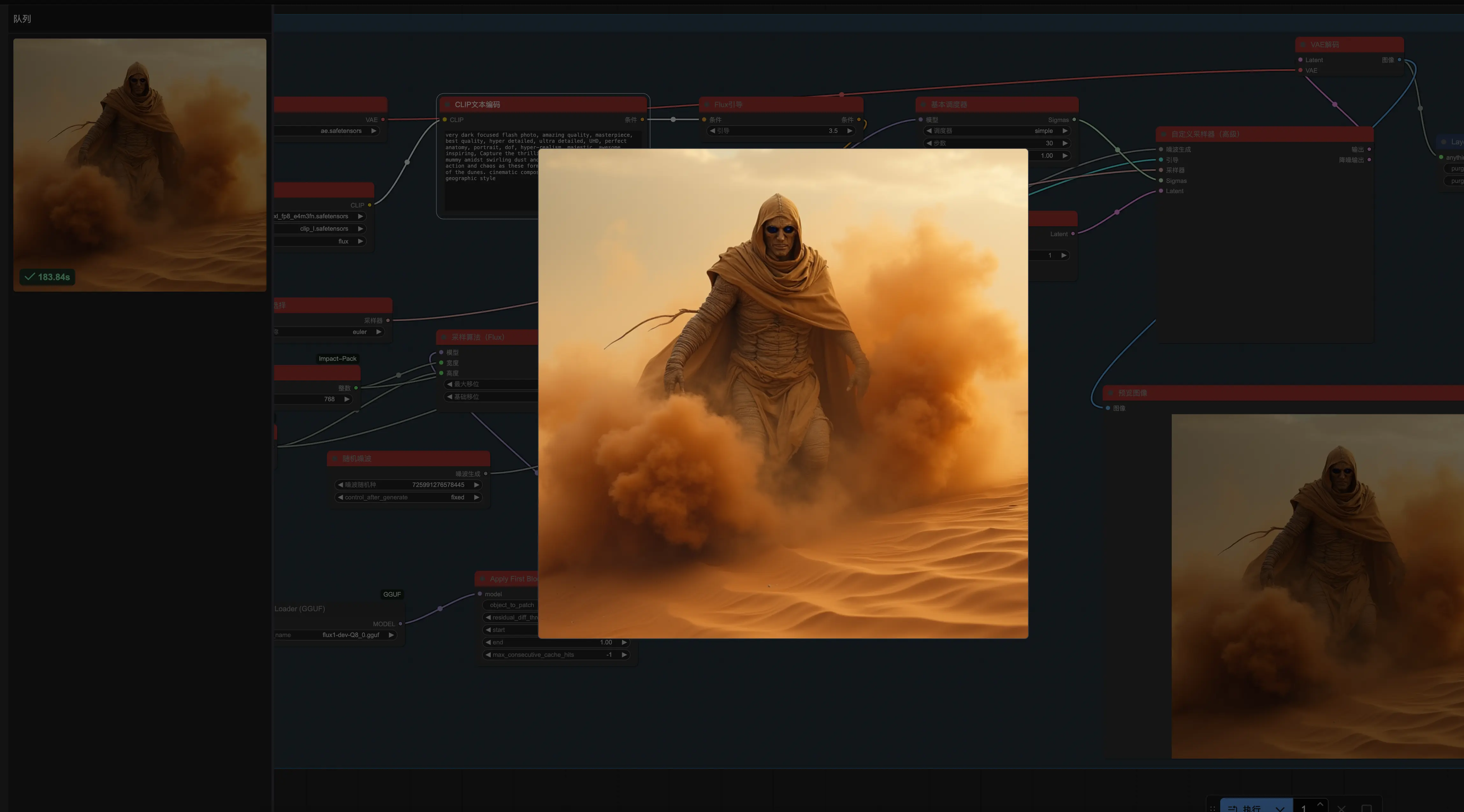
ComfyUI不能算是一个传统的文生图工具,而是一个高度可定制的工作流平台。它支持加载多种模型,我主要尝试了Flux模型。不过,在使用过程中遇到了一个“坑”:在Mac的Apple Silicon芯片上运行Flux模型时,FP8量化会出现报错,提示不支持apple silicon的芯片。尽管如此,通过使用GGUF量化模型以及TeaCache、WaveSpeed等加速技术,冷启动生成一张图的时间从240秒缩短到了180秒左右。ComfyUI的自定义能力非常强大,但对硬件性能要求较高,不适合在性能较低的终端上运行。
本地LLM工具体验
Ollama
Ollama肯定是每个接触本地LLM工具时绕不开的选择。它的最大优势在于方便,尤其是社区提供的各种模型可以直接通过pull命令下载,速度也很快。我尝试过最大671B的4bit量化DeepSeek-R1模型,运行效果令人满意。对于新手来说,Ollama确实是一个非常友好的选择。
vLLM
我希望通过vLLM尝试本地模型模拟OpenAI API类服务的工具,在多卡张量并行时,我遇到了一个比较棘手的问题:nccl报错。
|
|
能力有限,经过多次尝试和排查,暂时无法找到有效的解决方案。
SGLang
相比之下,SGLang在多卡调用表现得非常稳定,完全没有遇到类似的问题。
|
|
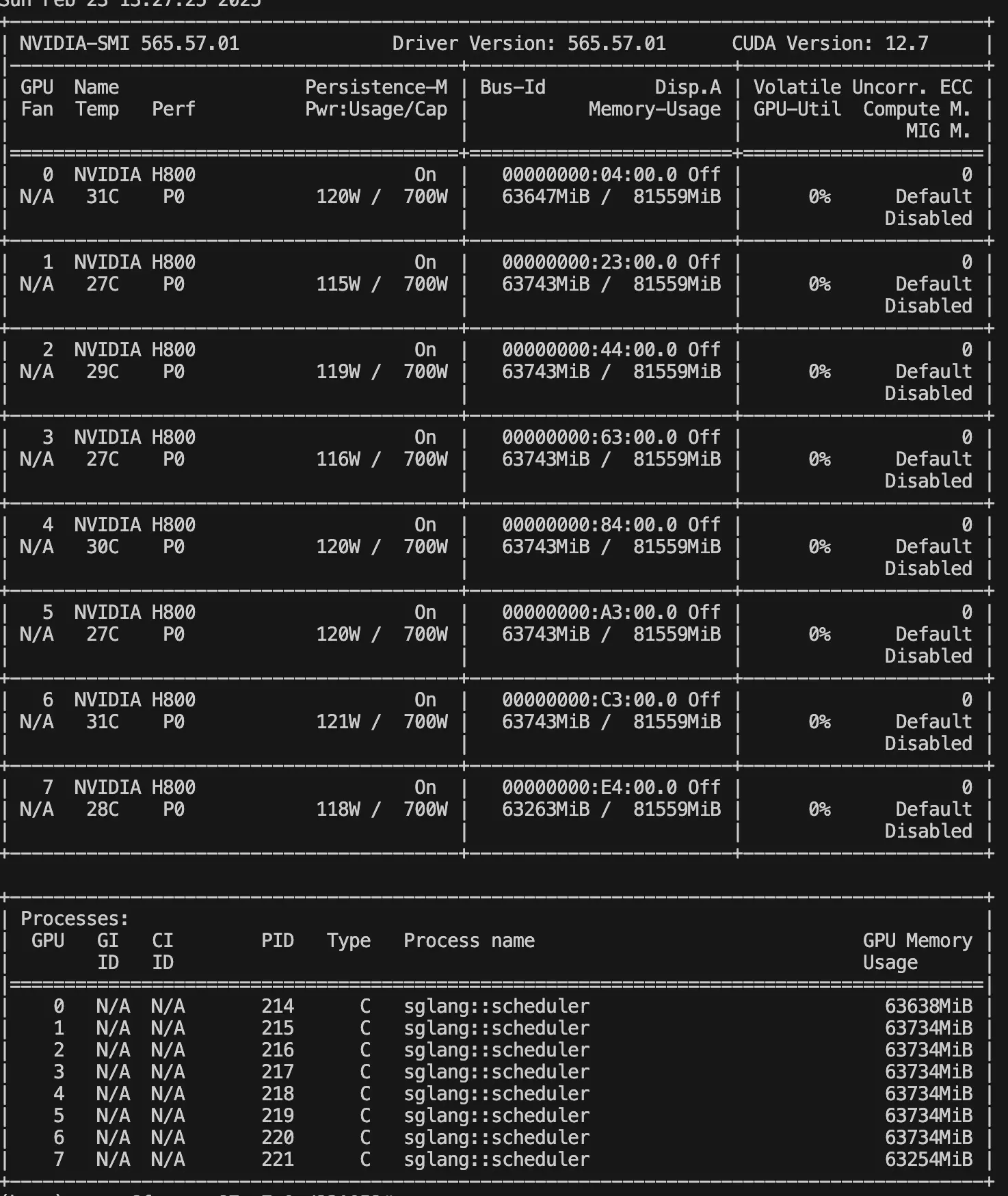
当我使用多卡运行本地模型时,SGLang的支持非常流畅,模型运行速度和稳定性都非常出色。通过使用SGLang,我还学习到了一些关于多卡张量并行、数据并行的知识,以及模型精度和上下文长度对KV缓存的影响。