TL;DR: 本文总结了个人近期折腾多款 AI 效率工具的实战体验。
- 文生图推荐(Mac 环境):如果你的设备是 Mac (Apple Silicon),强烈推荐使用界面友好且支持直接加载常用模型及 LoRA/ControlNet 配置的 Draw Things。高阶用户首选 ComfyUI,但注意避开 FP8 量化踩坑。
随着 AIGC 生态的爆发,在本地或自建算力节点上跑得动的高质量模型越来越多。作为一名技术折腾爱好者,我近期密集测试了目前最主流的一批图像生成工具与本地大语言模型 (LLM) 运行容器。在这篇文章中,我将分享每款产品在实际使用中的优缺点和踩坑记录,希望对准备进行本地化部署的开发者有所帮助。
第一部分:文生图工具体验
1. Mochi Diffusion
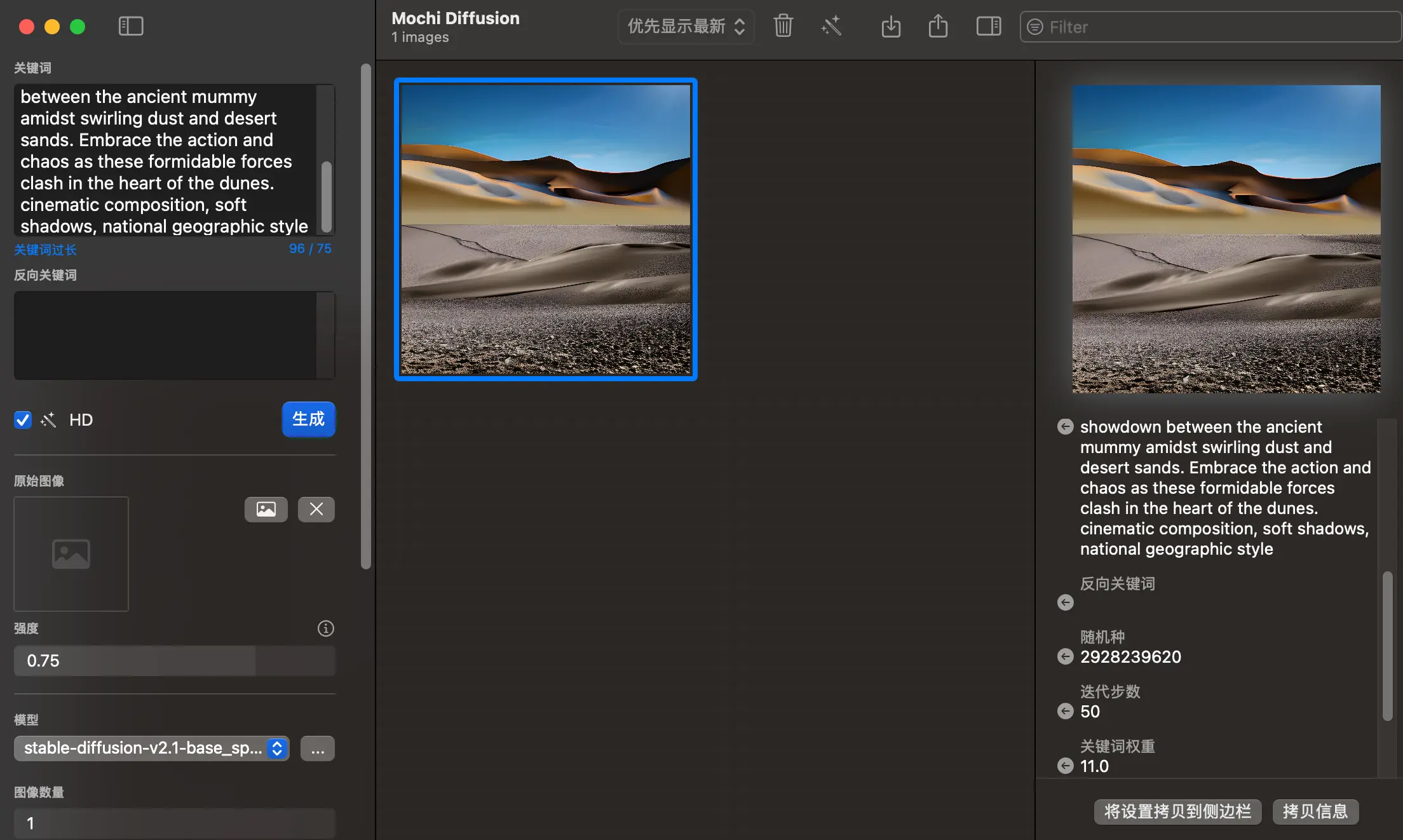
这是我入坑文生图接触的第一款工具,选择它的初衷是主打轻量、上手门槛低。从 Hugging Face 下载了几个 CoreML 格式转换的模型后,发现虽然确实能跑出图,但总体生成效果略显“抽象”。
它最大的亮点是推理全程不挑显卡 (GPU),主要通过调用 CPU 和 Apple 的 NPU 算力资源来进行渲染,这意味着即使没有高性能显卡,也能在轻薄本上跑起来。缺点也很明显:受限于硬件,出图速度比较慢,并且生态扩展性弱。客观来讲,并不是长久之计,目前主观不太推荐。
2. Draw Things
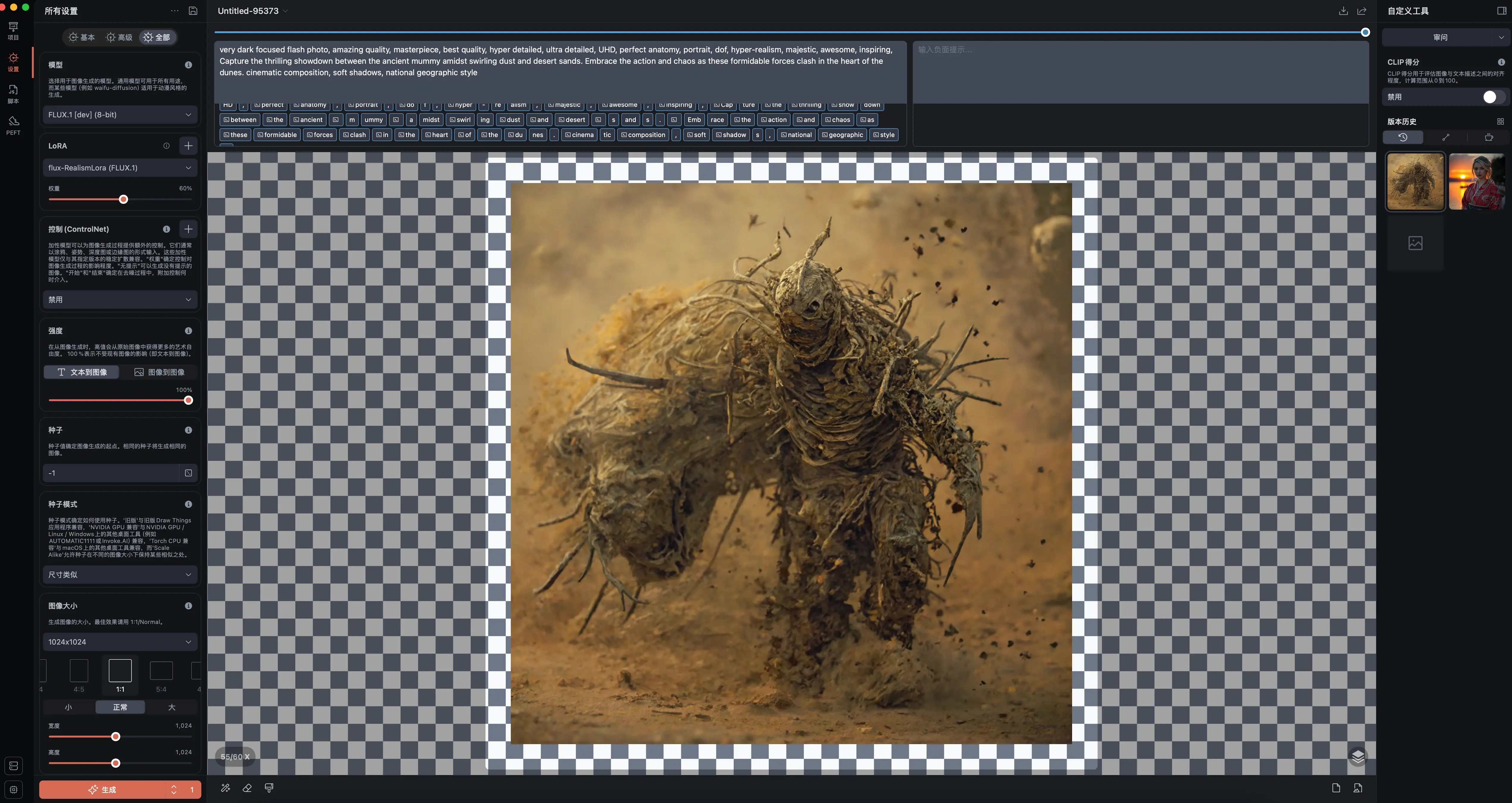
Draw Things 是一款极其优秀的“折中”且全面的解决方案。 软件内置了海量的云端模型可以直接下载(如 Llama 3, SDXL 等),而且原生支持用户自由灵活地设置各种参数。
它的功能极其完整,不仅能加载作者自行转换后的专属模型,更重要的是,它原生支持了 LoRA 权重加载和 ControlNet 控制功能。从实际运行而言,Draw Things 针对 Mac 系统底层的 Metal 框架优化得非常稳定流畅,且 UI 界面易用。综合而言,我认为它是目前 Mac 用户的首选文生图主力工具。
3. ComfyUI
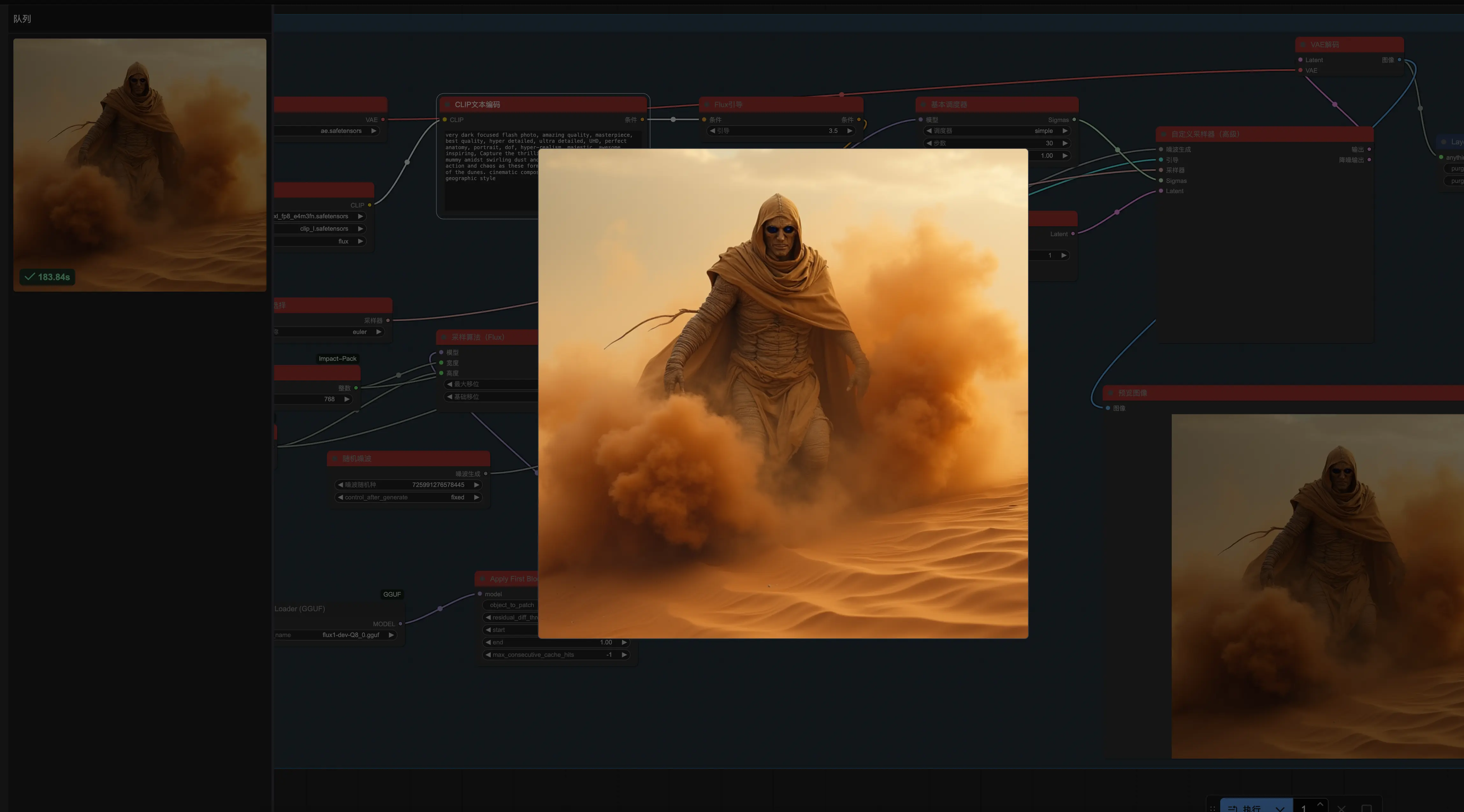
ComfyUI 严格意义上不能称为简单的软件,这是一个高度可定制化的节点式工作流平台。它支持市面上绝大多数开源模型,我重点尝试了近期大热的 Flux 模型。
不过在部署过程中我结实地踩了一个坑:在 Mac 的 Apple Silicon 系列芯片上强行运行 Flux 模型时,采用 FP8 量化会直接报错中断(底层框架暂不支持在该芯片上直接走 FP8)。
最终的解决方案是换成 GGUF 量化格式的模型,并搭配使用 TeaCache、WaveSpeed 等第三方工作流加速技术。经过优化,冷启动生成一张大图的时间从龟速的 240 秒大幅缩短到了 180 秒左右。
结论:ComfyUI 的自定义空间无敌,但它有着极高的学习曲线,同时也极度压榨主机的显存和浮点运算性能,不太适合配置一般的设备,但作为进阶玩家是必备利器。
第二部分:本地 LLM 大语言模型运行工具体验
1. Ollama
Ollama 是目前所有想要尝试本地 LLM 新手的首选“入坑神器”。
其最大的优势在于极简的类 Docker 体验体验和庞大的官方 Registry 生态。你只需要一行 pull 命令就可以把市面上各种不同量化版本的模型拖拽到本地运行,网络下载速度也做了很好的 CDN 优化。比如我曾经尝试过拉取并运行最大至 671B 规模参数的 4bit 量化满血版 DeepSeek-R1,不仅跑通了,性能表现也同样令人满意。强烈推荐用作单机验证和日常测试容器。
2. vLLM
在此之后,我尝试使用业界主流的高性能后端 vLLM 框架,它的初衷是想要在本地搭建并模拟出一套与 OpenAI 完全兼容的并发 API 接口服务。
然而,在配置多显卡加速(张量并行,Tensor Parallelism)时,我卡在了一个非常棘手的环境级错误上:频繁抛出 nccl 报错死锁。
|
|
受限于多卡环境的配置能力以及复杂的驱动栈,经过了多轮参数修正和环境排查,暂时未能找到针对该错误的有效解决方案,只好暂时将 vLLM 搁置。
3. SGLang (强烈推荐)
相比于在 vLLM 上遭遇反复挫折,同门“师兄弟” SGLang 框架在多显卡调度与并发控制上的表现则异常稳定且顺滑,上机配置后完全没有再遭遇任何进程级报错。
启动方式同样十分直接,参考官方文档调用模型拉起服务:
|
|
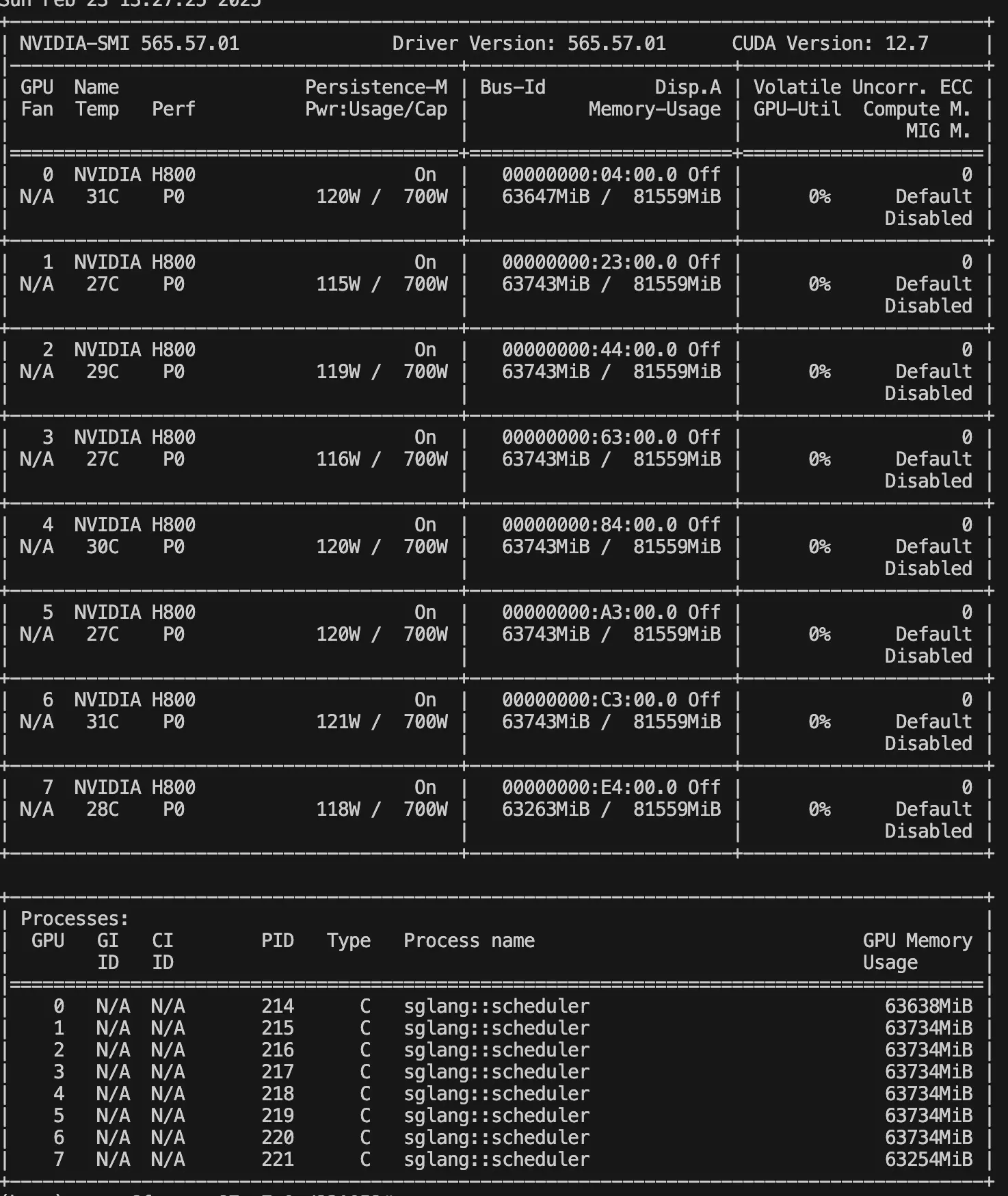
当我采用多卡(张量并行深度切分)运行大规模本地模型时,SGLang 的底层支撑十分流畅,整个推理生成的速度、Token 的吞吐量和长连接稳定性都极其出色。此外,折腾 SGLang 框架也强行逼着我学习和实操了许多大模型集群部署中的进阶知识,比如:什么是张量并行 (TP) 与数据并行 (DP)、模型精度衰减的影响,以及极端长上下文 (Context-Length) 是如何吞噬且影响 KV Cache 剩余可用空间的。
如果你有分布式或较高压力的微调/推理诉求,我更偏爱并推荐 SGLang 成为你的后端基础设施引擎。